Phrame
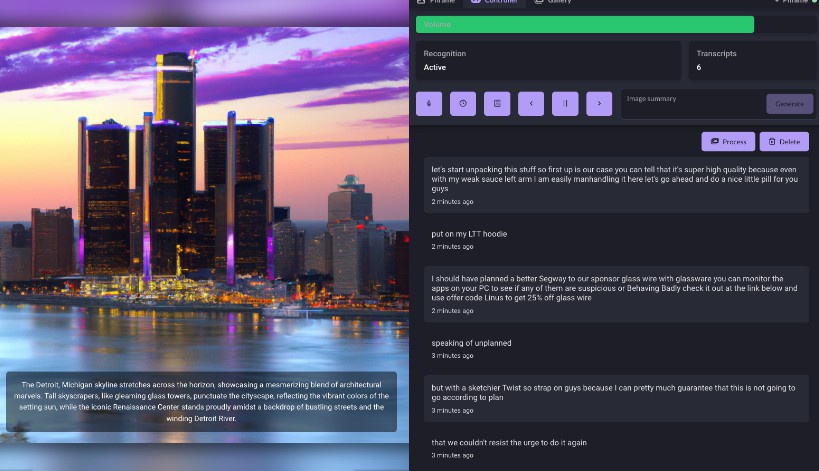
Phrame generates captivating and unique art by listening to conversations around it, transforming spoken words and emotions into visually stunning masterpieces. Unleash your creativity and transform the soundscape around you.





How
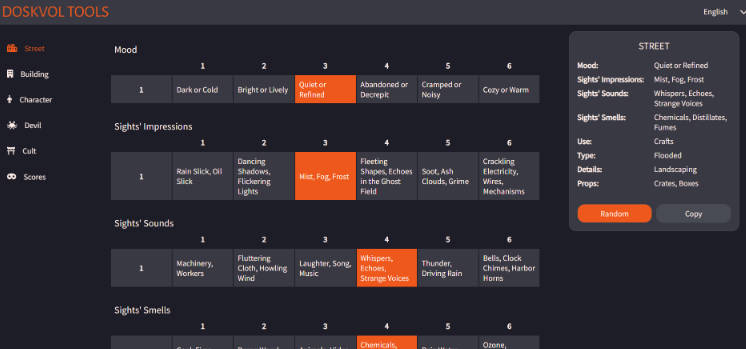
Phrame relies on the SpeechRecognition interface of the Web Speech API to transform audio into text. This text is processed by OpenAI, producing a condensed summary. The summary is then combined with the configured generative AI image services and the final images are saved.
Donations
If you would like to make a donation to support development, please use GitHub Sponsors.
Minimum Requirements
Phrame can be used without a microphone and any modern browser will work. However, if you would like to use speech recognition, you will need a compatible browser.
Features
- Responsive UI and API bundled into single Docker image
- Websockets provide instant updates and remote control
- Built in config editor
- Support for multiple AI services
- Voice commands
Supported Architecture
- amd64
- arm64
- arm/v7
Supported AIs
Voice Commands
Interact with Phrame by using the following voice commands.
| Command | Action |
|---|---|
Hey Phrame |
Wake word to generate images on demand |
Next Image |
Advance to next image |
Previous Image |
Advance to previous image |
Last Image |
Advance to previous image |
Usage
Docker Compose
version: '3.9'
volumes:
phrame:
services:
phrame:
container_name: phrame
image: jakowenko/phrame
restart: unless-stopped
volumes:
- phrame:/.storage
ports:
- 3000:3000
Configuration
Configurable options are saved to /.storage/config/config.yml and are editable via the UI at http://localhost:3000/config.
Note: Default values do not need to be specified in configuration unless they need to be overwritten.
image
# image settings (default: shown below)
image:
# time in seconds between image animation
interval: 60
# order of images to display: random, recent
order: recent
transcript
Images are generated by processing transcripts. This can be scheduled with a cron expression. All of the transcripts within X minutes will then be processed by OpenAI using openai.chat.prompt to summarize the transcripts.
# transcript settings (default: shown below)
transcript:
# schedule as a cron expression for processing transcripts (at every 30th minute)
cron: '*/30 * * * *'
# how many minutes of files to look back for (process the last 30 minutes of transcripts)
minutes: 30
# minimum number of transcripts required to process
minimum: 5
openai
To configure OpenAI, obtain an API key and add it to your config like the following. All other default settings found bellow will also be applied. You can overwrite the settings by updating your config.yml file.
# openai settings (default: shown below)
openai:
key: sk-XXXXXXX
chat:
# model name (https://platform.openai.com/docs/models/overview)
model: gpt-3.5-turbo
# the prompt used to generate a summary
prompt: You are a helpful assistant that will take a string of random conversations and pull out a few keywords and topics that were talked about. You will then turn this into a short description to describe a picture, painting, or artwork. It should be no more than two or three sentences and be something that DALL·E can use. Make sure it doesn't contain words that would be rejected by your safety system.
image:
# size of the generated images: 256x256, 512x512, or 1024x1024
size: 512x512
# number of images to generate for each style
n: 1
# used with summary to generate image (summary, style)
style:
- cinematic
stabilityai
To configure Stability AI, obtain an API key and add it to your config like the following. All other default settings found bellow will also be applied. You can overwrite the settings by updating your config.yml file.
# stabilityai settings (default: shown below)
stabilityai:
key: sk-XXXXXXX
image:
# number of seconds before the request times out and is aborted
timeout: 30
# engined used for image generation
engine_id: stable-diffusion-512-v2-1
# width of the image in pixels, must be in increments of 64
width: 512
# height of the image in pixels, must be in increments of 64
height: 512
# how strictly the diffusion process adheres to the prompt text (higher values keep your image closer to your prompt)
cfg_scale: 7
# number of images to generate
samples: 1
# number of diffusion steps to run
steps: 50
style:
- cinematic
time
# time settings (default: shown below)
time:
# defaults to iso 8601 format with support for token-based formatting
# https://github.com/moment/luxon/blob/master/docs/formatting.md#table-of-tokens
format:
# time zone used in logs
timezone: UTC
logs
# log settings (default: shown below)
# options: silent, error, warn, info, http, verbose, debug, silly
logs:
level: info
telemetry
# telemetry settings (default: shown below)
# self hosted version of plausible.io
# 100% anonymous, used to help improve project
# no cookies and fully compliant with GDPR, CCPA and PECR
telemetry: true
Development
Run Local Services
| Service | Command | URL |
|---|---|---|
| UI | npm run local:frontend |
localhost:8080 |
| API | npm run local:api |
localhost:3000 |
Build Local Docker Image
./.develop/build