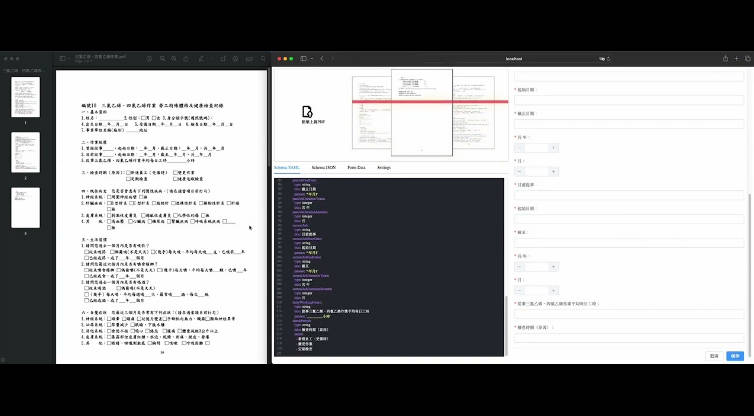
PDF to Digital Form using GPT4 Vision API
A POC that uses GPT 4 Vision API to generate a digital form from an Image using JSON Forms from https://jsonforms.io/
Inspired by:
- screenshot-to-code:https://github.com/abi/screenshot-to-code
- draw-a-ui:https://github.com/SawyerHood/draw-a-ui
Both repositories demonstrate that the GPT4 Vision API can be used to generate a UI from an image and can recognize the patterns and structure of the layout provided in the image.
Demo
Click the thumbnail to watch on YouTube:
Running using Local Environment ?
Frontend
cdinto frontend directory
cd ai-json-form
- Install Packages and run
npm install
npm run dev
Backend
cdinto directory
cd backend
- Install Packages
poetry install
# alternatively, you can use pip install
pip install -r requirements.txt
- Setup Environment Variables
export OPENAI_API_KEY=
# optional
export OPENAI_ORG=
If you plan to use the Mock response only, you should set OPENAI_API_KEY to any value.
- Run
python main.py
Running using Docker ?
- export the environment variables
echo "OPENAI_API_KEY=YOUR_API_KEY" > .env
# The following is optional
echo "OPENAI_ORG=YOUR_ORG" >> .env
- Run the docker-compose
docker-compose up --build
- Open the browser and visit
http://localhost:8080/aijsv/
Disclaimer
I am new to Vue, so the code might not be the best practice. I am still learning and improving. Should you have any suggestions, please feel free to PR.
Flow Explain
-
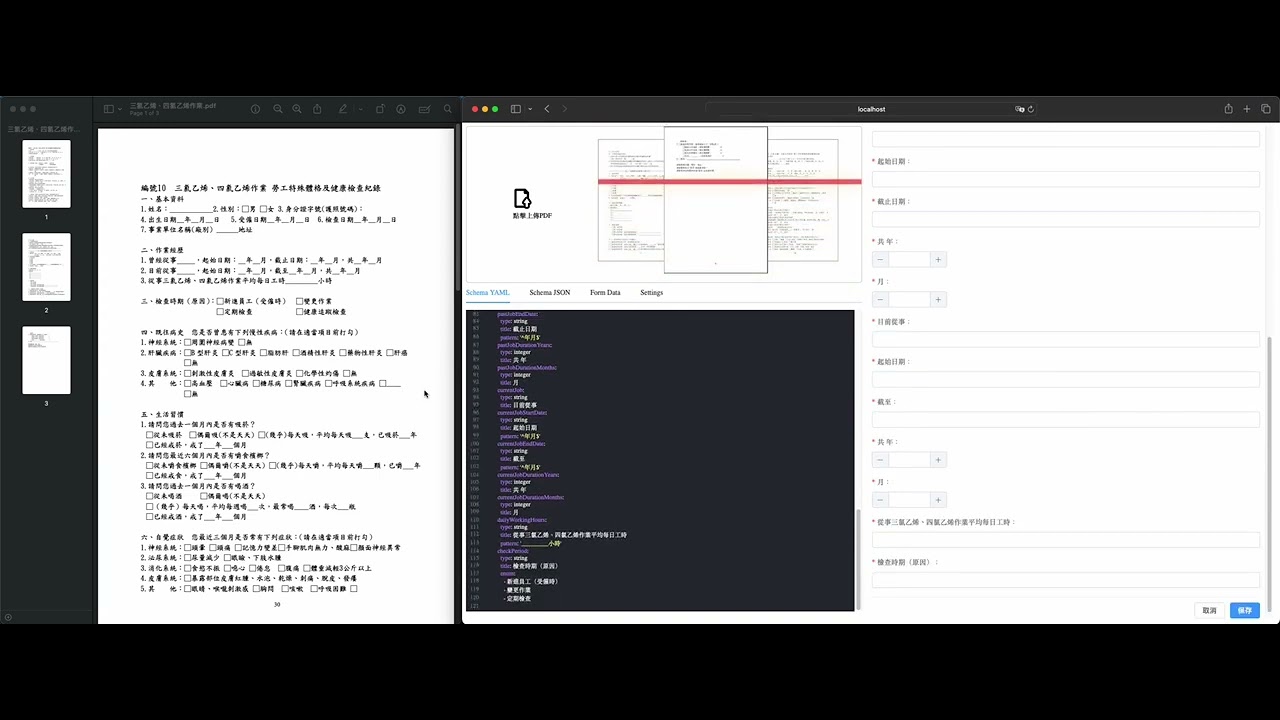
Upload PDF files of up to three pages from the frontend
If you want to adjust the number of pages, you can change the
MAX_PDF_PAGESvariable inbackend/app/socket.py -
When the backend receives the PDF file in Base64 string format, it does the following processes:
- Convert the URL String Back to Bytes
- Read the PDF file, convert it to a JPG image, and save it to the /tmp folder using the package
pdf2image. - Extract the strings from the same PDF file using the package
PyPDF2. The extracted strings will become part of the prompt sent to the GPT4 model to enhance accuracy. - Prepare the prompts and send them along with the PDF screenshot to the GPT4 Vision API
- Send the chunk to the frontend via Socket.IO incrementally.
-
Whenever the frontend receives the chunk, it appends it to the
codemirroreditor, and checks if the current content is a valid YAML. If it’s a valid YAML, it will apply it to the JSON Scheme to force the UI to re-render.