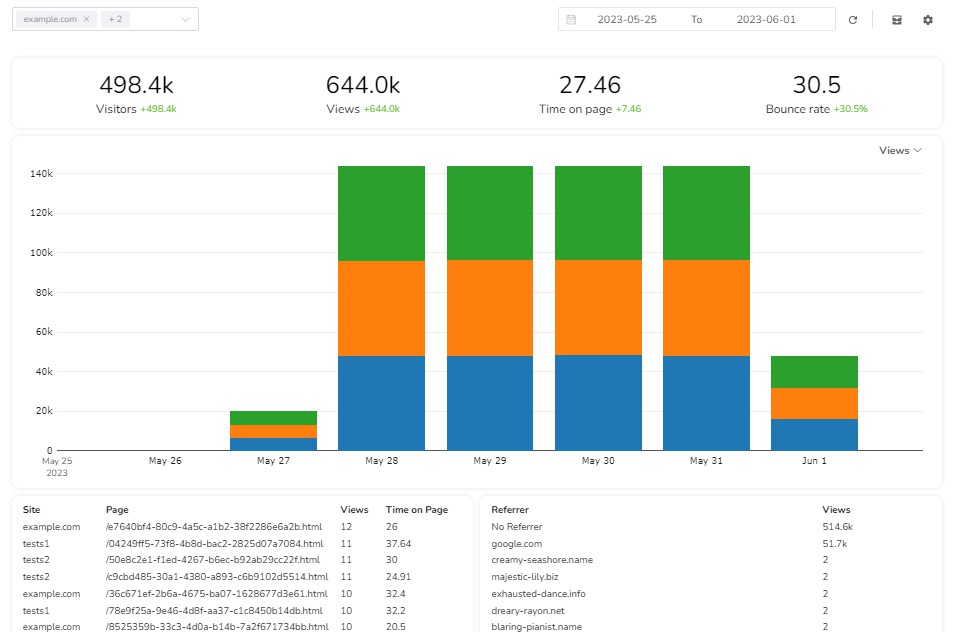
Serverless Website Analytics
This is a CDK serverless website analytics construct that can be deployed to AWS. This construct creates backend, frontend and the ingestion APIs.
This solution was designed for multiple websites with low to moderate traffic. It is designed to be as cheap as possible, but it is not free. The cost is mostly driven by the ingestion API that saves the data to S3 through a Kinesis Firehose.
You can see a LIVE DEMO HERE.
Objectives
- Easy to deploy in your AWS account, any *region
- The target audience is small to medium websites with low to moderate traffic (less than 10M views)
- Lowest possible cost
- KISS
- No direct server-side state
- Low maintenance
The main objective is to keep it simple and the operational cost low, keeping true to “scale to 0” tenants of serverless, even if it goes against “best practices”.
Getting started
Serverside setup
⚠️ Requires your project
aws-cdkandaws-cdk-libpackages to be greater than 2.79.1
Install the CDK construct library in your project:
npm install serverless-website-analytics
Add the construct to your stack:
import { ServerlessWebsiteAnalytics } from 'serverless-website-analytics';
export class App extends cdk.Stack {
constructor(scope: Construct, id: string, props?: cdk.StackProps) {
super(scope, id, props);
...
new Swa(this, 'swa-demo-codesnippet-screenshot', {
environment: 'prod',
awsEnv: {
account: this.account,
region: this.region,
},
sites: ['example.com', 'tests1', 'tests2'],
allowedOrigins: ['*'],
/* None and Basic Auth also available, see options below */
auth: {
cognito: {
loginSubDomain: 'login',
users: [
{ name: '<full name>', email: '<[email protected]>' },
]
}
},
/* Optional, if not specified uses default CloudFront and Cognito domains */
domain: {
name: 'demo.serverless-website-analytics.com',
certificate: wildCardCertUsEast1,
/* Optional, if not specified then no DNS records will be created. You will have to create the DNS records yourself. */
hostedZone: route53.HostedZone.fromHostedZoneAttributes(this, 'HostedZone', {
hostedZoneId: 'Z00387321EPPVXNC20CIS',
zoneName: 'demo.serverless-website-analytics.com',
}),
}
});
}
}
Quick option rundown:
sites: The list of allowed sites. This does not have to be a domain name, it can also be string. It can be anything you want to use to identify a site. The client-side script that sends analytics will have to specify one of these names.allowedOrigins: The origins that are allowed to make requests to the backend Ingest API. This CORS check is done as an extra security measure to prevent other sites from making requests to your backend. It must include the protocol and full domain. Ex: If your site isexample.comand it can be accessed usinghttps://example.comandhttps://www.example.comthen both need to be listed. A value of*specifies all origins are allowed.auth: Defaults to none. If you want to enable auth, you can specify either Basic Auth or Cognito auth but not both.undefined: If not specified, then no authentication is applied, everything is publicly available.basicAuth: Uses a CloudFront function to validate the Basic Auth credentials. The credentials are hard coded in the Lambda function. This is not recommended for production, it also only secures the HTML page abd API is still accessible without auth.cognito: Uses an AWS Cognito user pool. Users will get a temporary password via email after deployment. They will then be prompted to change their password on the first login. This is the recommended option for production as it uses JWT tokens to secure the API as well.
domain: If specified, it will create the CloudFront and Cognito resources at the specified domain and optionally create the DNS records in the specified Route53 hosted zone. If not specified, it uses the default autogenerated CloudFront(cloudfront.net) and Cognito(auth.us-east-1.amazoncognito.com) domains. You can read the website URL from the stack output.
For a full list of options see the API.md docs.
You can see an example implementation of the demo site here
Client side setup
⚠️ IMPORTANT! After the client sent the first page data, you have to click on the “Add Partitions” button in the frontend to auto-discover and add the site, month and day partitions. Otherwise, the data will not show up in the charts. This operation has to be repeated at the beginning of every month.
Install the client-side library:
npm install serverless-website-analytics-client
Irrelevant of the framework, you have to do the following to track page views on your site:
- Initialize the client only once with
analyticsPageInit. The site name must correspond with the one that you specified when deploying theserverless-website-analyticsbackend. You also need the URL to the backend. Make sure your frontend site’sOriginis whitelisted in the backend config. - On each route change call the
analyticsPageChangefunction with the name of the new page.
The following sections show you how to do it in Vue, see the readme of the client for various framework setups.
Vue
./serverless-website-analytics-client/usage/vue/vue-project/src/main.ts
...
import * as swaClient from 'serverless-website-analytics-client';
const app = createApp(App);
app.use(router);
swaClient.v1.analyticsPageInit({
inBrowser: true, //Not SSR
site: "<Friendly site name>", //example.com
apiUrl: "<Your serverless-website-analytics URL>", //https://my-serverless-website-analytics-backend.com
// debug: true,
});
router.afterEach((event) => {
swaClient.v1.analyticsPageChange(event.path);
});
app.mount('#app');
What’s in the box
The architecture consists of four components: frontend, backend, ingestion API and the client JS library.

See the highlights and design decisions sections in the CONTRIBUTING file for detailed info.
Frontend
AWS CloudFront is used to host the frontend. The frontend is a Vue 3 SPA app that is hosted on S3 and served through CloudFront. The Element UI Plus frontend framework is used for the UI components and Plotly.js for the charts.



Backend
This is a Lambda-lith hit through the Lambda Function URLs (FURL) by reverse proxying through CloudFront. It is written in TypeScript and uses tRPC to handle API requests.
The Queries to Athena are synchronous, the connection timeout between CloudFront and the FURL has been increased to 60 seconds.
There are three available authentication configurations:
- None, it is open to the public
- Basic Authentication, basic protection for the index.html file
- AWS Cogntio, recommended for production
⚠️ Partitions are not automatically created in Athena, they have to be created manually by the user by clicking the “Create/Refresh Partitions” button in the frontend. This has to be done whenever a new site is added or a new month starts.
Ingestion API
Similarly to the backend, it is also a TS Lambda-lith that is hit through the FURL by reverse proxying through CloudFront. It also uses tRPC but uses the trpc-openapi package to generate an OpenAPI spec. This is used to generate the API types used in the client JS package. and can also be used to generate other language client libraries.
The lambda function then saves the data to S3 through a Kinesis Firehose. The Firehose is configured to save the data in a partitioned manner, by site, year and month. The data is saved in parquet format, buffered for 1 minute, which means the date will be stored after about 1min ± 1min.
Location data is obtained by looking the IP address up in the MaxMind GeoLite2 database. We don’t store any Personally Identifiable Information (PII) in the logs or S3, the IP address is never stored.
Sponsors
Proudly sponsored by:
- Cloud Glance – A Single pane of glass for all your AWS credentials and more.
- Interested in sponsoring?
Contributing
See CONTRIBUTING.md for more info on how to contribute + design decisions.
Roadmap
Can be found in the here